(译)深入了解React Fiber的内部


原文链接:A deep dive into React Fiber internals - LogRocket Blog
有没有想过当你调用ReactDOM.render(<App />, document.getElementById('root'))发生了什么?
我们知道ReactDom在后台构建DOM树,并将应用渲染到屏幕上。但是ReactDom是怎么构建DOm树的?当app的state改变时,它是如何更新树?
在这篇文章中,我开始从React在15.0.0之前如何构建DOM树,这个模型的陷阱以及在16.0.0的新模型中如何解决这些问题。这篇文章会涵盖很多内部实现细节的概念,它对于使用React进行实际的开发不是必要的。
Stack reconciler
让我们从熟悉的ReactDOM.render(<App />, document.getElementById('root'))开始。
ReactDOM模块将<App />传给reconciler,这里有两个问题:
<App />指的什么?- reconciler是什么
让我们解开这两个问题:<App />是一个react元素,也是元素描述树(lements describe the tree)。
元素是描述组件的实例或DOM节点及其所需属性的普通对象。 –React Blog
换句话来说,元素不是真正的DOM节点或者组件实例。它们只是用来向React描述它们是什么元素类型,有什么属性,子节点是什么的一种方法。
这就是React的真正力量所在。React消除了如何构建、渲染、管理真正DOM树的生命周期的复杂部分,简化开发人员的工作。要了解他们的真正含义,让我们看一下使用面向对象的概念。
在典型的面向对象世界中,开发者需要实例化和管理每个DOM元素的生命周期。例如,你想要创建一个简单的表单和一个提交按钮,那么状态管理甚至是简单的操作都需要开发人员的努力。
假设Button组件有一个状态变量isSubmitted,Button的生命周期类似于以下的流程图,其中的每个状态都需要app处理:
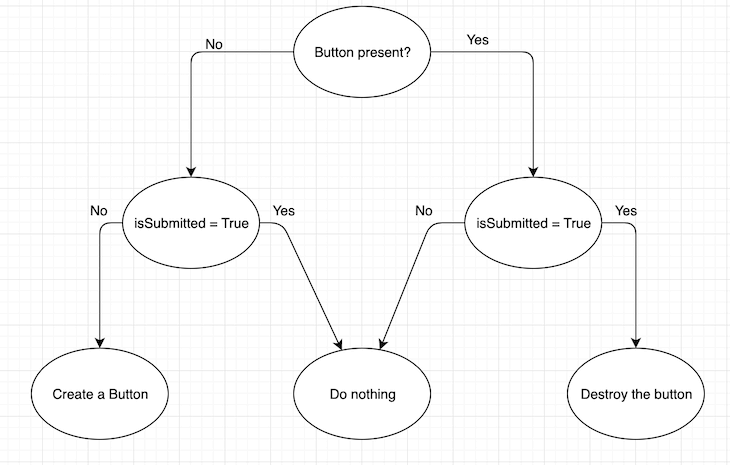
流程图的大小和代码的行数随着状态变量的增加而呈指数级上升。
React有精确解决此问题的元素,在React中,有两种类型的元素:
- DOM元素:当元素的类型是一个字符串的时候,例如:
<button class="okButton"> OK </button> - Component元素:当类型是一个类或者函数的时候,例如
:<Button className="okButton"> OK </Button>,这里Button是一个类组件或者函数组件,这是我们用的典型的React组件。
理解两种类型(class or function)是一个简单的对象是非常重要的。它们仅仅描述在屏幕上需要渲染什么,在你创建或者实例化的时候不会导致任何渲染的发生。这对于React解析和遍历它们来构建DOM树是非常容易的。当遍历完成后才会发生实际的渲染。
当React遇到一个class或者函数组件时,会根据组件的props去确定它需要渲染哪个元素。例如,如果<App />如下:
<Form>
<Button>
Submit
</Button>
</Form>
React会根据相应的props确定<Form>和<Button>渲染内容。例如,Form组件是一个函数组件,看起来是这样:
const Form = (props) => {
return(
<div className="form">
{props.form}
</div>
)
}
React会调用render()来确定它渲染的元素,并最终看到它渲染一个带有child的<div>。React将重复这个过程,直到确定页面上的每个组件的基础DOM标签元素。
递归遍历一棵树来确定React应用程序组件树的底层DOM标签元素的过程称为reconciliation。在reconciliation结束后,React知道了DOM树的结果和像react-dom或react-native这样的渲染器更新DOM节点所需的最小变更集。
这意味着当你调用ReactDOM.render()或者setState的时候,React将执行一个reconciliation。在setState的情况下,它执行遍历,并将新树和老树进行比较后找出变化。接着,它在现在的树上应用这些变化,从而更新成调用setState相应的状态。
现在我们理解reconciliation是什么了,现在让我们看一下这个模型的陷阱。
顺便说一句,为什么叫做the “stack” reconciler?
这个名字来源于stack数据结构,它是后进先出的机制。stack和我们刚才看的有什么关系吗?好吧,事实证明,由于我们实际上做了递归,因此它和stack有关系。
Recursion(递归)
要了解为什么会发生这个情况,让我们举一个简单的例子来看一下调用栈(call stack)发生了什么
function fib(n) {
if (n < 2){
return n
}
return fib(n - 1) + fib (n - 2)
}
fib(10)
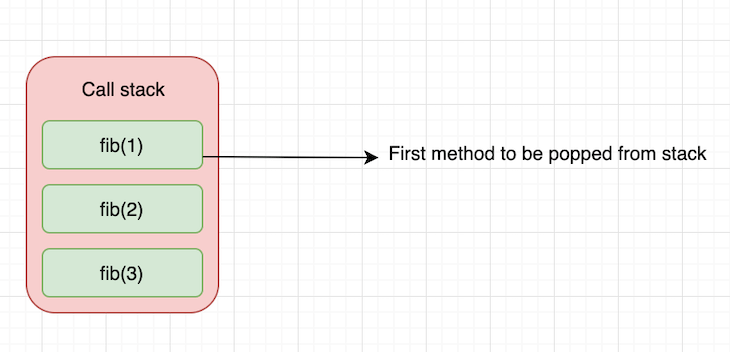
正如我们看到的这样,调用栈会将每次fib()的调用push进栈中,直到弹出要返回的第一个函数调用fib(1)。然后它继续push递归调用,并在到达return语句的时候弹出。这样它有效的使用堆栈,直到fib(3)返回成为最后一个从栈中pop的最后一个元素。
我们刚刚就看到的reconciliation算法是纯递归算法。子树的更新会立即重新渲染。虽然这很好用,但是有一些限制。正如Andrew Clark所说:
- 在一个UI中,每次的更新立即应用是不必要的,事实上,这样做很浪费会导致帧下降,降低用户的体验。
- 不同类型的更新有不同的优先级 - 一个动画的更新需要比数据更新更快的完成
现在,我们说的掉帧是什么意思?为什么递归方法有问题?为了掌握这一点,让我从用户的体验角度简要说明什么是帧频(frame rate)以及它为什么这么重要。
帧频是指连续图像显示在屏幕上的频率,我们在电脑屏幕上看到的一切是由在屏幕上以瞬时出现的速率播放的图像或帧组成。
为了理解它,可以将电脑显示器想像成翻书,当你翻书时,将每一页视为一定速率播放的帧。换句话来说,电脑屏幕只是一本自动翻页的书,会一直播放屏幕的变化。如果还不能理解,请看下面的视频(这是xx的一个视频,下面用图片代替)。

通常情况下,人眼看视频会感觉流畅的话,视频需要以每秒30帧(FPS)的速率播放。更高的速率会有更好的体验。这是为什么游戏玩家更喜欢第一人称精确射击游戏中更高帧频主要的原因。
话说回来,现在的大多数设备刷新屏幕在60帧,或者换句话说,1/60=16.67ms,这意味着每16ms显示一个新的帧。这个数字是非常重要的,因为React在屏幕上渲染超过16ms的话,浏览器就会掉帧。
事实上,浏览器还有一些基础工作要做,所以你的操作必须在10ms内完成。如果你没有办法满足这个要求,帧就会下降,屏幕上的内容会显得特别乱。这会对用户的体验产生了负面的影响。
当然,这不是静态和文本内容引起注意的重要原因。但是在显示动画的情况下,这个数字至关重要。所以如果React的reconciliation算法每次遍历整个App树后,有更新就重新render。如果遍历超过16ms,就会导致掉帧。
这是为什么最好按优先级对更新进行分类,而不是盲目地将传递给reconciliation的每个更新都应用的重要原因。还有一个好的特性是在下一帧中暂停和恢复。这样,React能使用16ms的预算更好的控制渲染。
以上使React团队重写reconciliation算法,新算法叫做Fiber。我希望现在对于Fiber的为什么存在以及具有的意义有了进一步的认识。出现在让我们看一下Fiber是如何解决这个问题的。
How Fiber works
现在我们知道了开发Fiber的动机,让我们总结一下它需要实现的功能。
同样,我引用Andrew Clark的笔记:
- 为不同类型分配不用的优先级
- 暂停并稍后恢复它
- 如果不需要的话,能终止
- 复用之前完成的工作
实现这样的事情的挑战之一是JavaScript引擎的工作方式,并且在js中某种程度上缺乏这样的线程。为了理解这个,让我们探索一下JS引擎是如何处理执行上下文。
JavaScript execution stack
每当你在js中写一个函数,当我们调用函数的时候,js引擎创建了执行上下文。每次js引擎开始,它会创建一个全局上下文,它包含全局对象,例如浏览器中的window对象、nodejs的global对象。在js中,这些上下文使用stack数据结构来处理。
所以,当你写以下代码时:
function a() {
console.log("i am a")
b()
}
function b() {
console.log("i am b")
}
a()
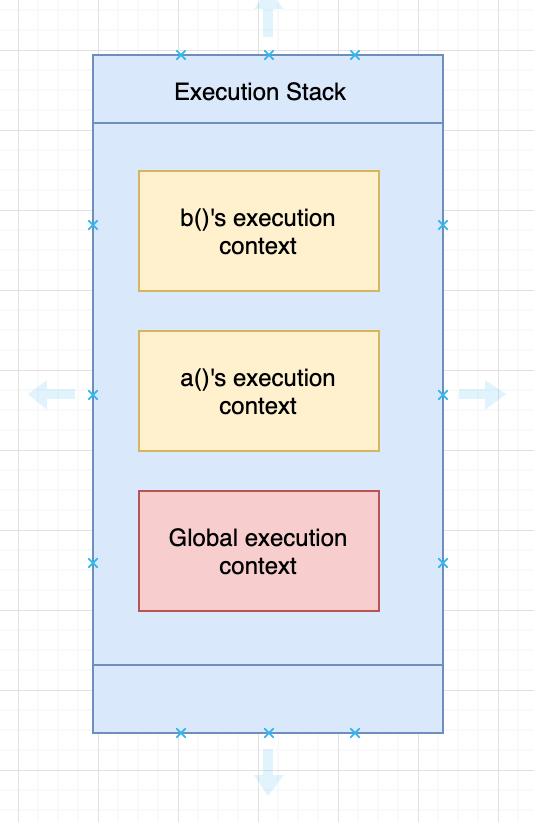
Js引擎首先创建一个全局上下文,并push进执行栈(the execution stack)中。接着它创建函数a()的函数执行上下文,因为a()中调用了b(),所以它将创建b()的函数执行上下文,并push进栈中。
当函数b()返回时,引擎会销毁b()的上下文,当我们从a()中退出,a()的上下文被销毁。执行期间的栈看起来像这样:
但是当浏览器有了一个异步事件例如http request,会发生什么?js引擎是否会存进栈中来处理异步事件,等待事件的完成?
JS引擎在这里做了不同的处理,在执行栈的最上面,js引擎还有一个queue的数据结构,也称为事件队列。事件队列处理异步事件的调用,例如浏览器中的http或者网络事件。
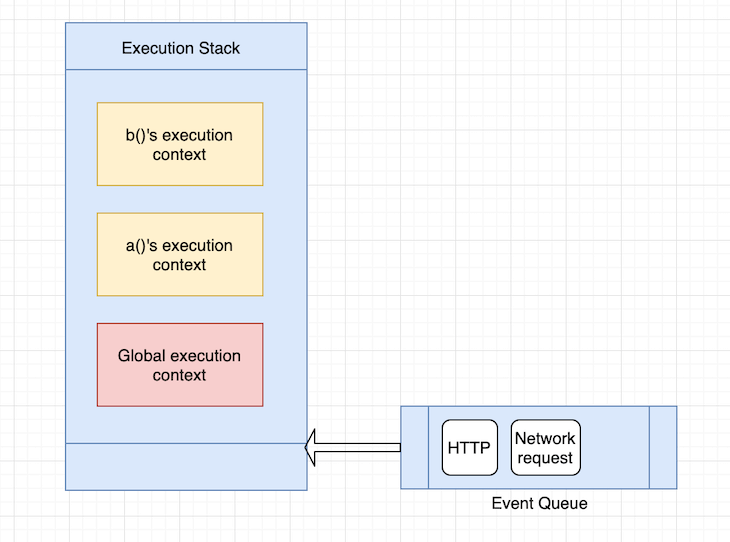
Js引擎处理队列的方式是等待执行栈为空。所以每次执行栈变空的时候,js引擎会查看事件队列,pop出里面的item,然后执行它。重要的是要注意:JS引擎仅仅当执行栈为空或者执行栈中只有全局执行上下文是去检查事件队列。
尽管我们将它们称为异步事件,但这里有一个细微的区别:事件相对于何时进入队列是异步的,但相对于它们何时真正得到处理则并不是真正异步的。
回到stack reconciler,React遍历树是在执行栈中做的。所以当计算更新完成后,它们会放到事件队列中。只有当执行栈为空的时候,更新才会被执行。这正是Fiber解决的问题,几乎要实现栈的暂停、恢复、停止的智能功能。
再次引用 Andrew Clark的笔记:
Fiber is reimplementation of the stack, specialized for React components. You can think of a single fiber as a virtual stack frame.
The advantage of reimplementing the stack is that you can keep stack frames in memory and execute them however (and whenever) you want. This is crucial for accomplishing the goals we have for scheduling.
Aside from scheduling, manually dealing with stack frames unlocks the potential for features such as concurrency and error boundaries. We will cover these topics in future sections.
简单来说,Fiber是具有自己虚拟栈的工作单元。在之前实现的reconciliation短发中,React创造了一个不可变的树对象,然后递归的遍历它。
在现在的实现中,React创建一个可修改的fiber节点树,fiber节点描述了组件的state、props以及需要渲染的底层DOM元素。
而且由于fiber节点是能改变的,React不需要为更新再创建每一个节点,当有更新时,它可以简单的克隆和更新节点。另外,如果是fiber树,React不会做递归遍历,而是,它创建一个单链表做父亲优先、深度优先的遍历。
Singly linked list of fiber nodes
fiber节点代表栈中的帧(stack frame),也代表React组件的一个示例,一个fiber节点包含以下属性:
Type
div,span等,例如基础组件(host components)或者class、funciton的组合组件
Key
与传递给React组件的key一样
Child
当我们调用组件的render返回的元素, 例如:
const Name = (props) => {
return(
<div className="name">
{props.name}
</div>
)
}
这里Name的child是div,因为它返回的是一个div元素
Sibling
表示render返回的元素列表情况
const Name = (props) => {
return([<Customdiv1 />, <Customdiv2 />])
}
在上面的例子中,<Customdiv1 />和<Customdiv2 />是<Name>的child。<Customdiv1 />的Subling是<Customdiv2 />,它们形成单链表。
Return
表示返回的栈中的帧,从逻辑上讲,返回的是父fiber节点,因此它代表的是父亲。例如上面例子中Customdiv1的return指向Name
pendingProps and memoizedProps
备份(Memoization)意味着存储函数执行的结果以便后续的使用,从而避免重复计算。pendingProps代表传递给组件的props,memoizedProps在执行栈的末尾初始化,并存储该节点的props。
当传入的pendingProps和memoizedProps相等时,代表fiber之前的输出可以被重用,避免不必要的工作。
pendingWorkPriority
表示Fiber代表的工作优先级的数字,ReactPriorityLevel模块列出了不同优先级以及它的含义。除NoWork为零外,数字越大表示优先级越低。
例如,你可以使用以下函数来检查fiber的优先级是否至少与给定级别一样高。调度程序使用优先级字段来搜索要执行的下一个工作单元。
function matchesPriority(fiber, priority) {
return fiber.pendingWorkPriority !== 0 &&
fiber.pendingWorkPriority <= priority
}
Alternate
在任何时候,一个组件的实例最多对应两个fiber:当前的fiber和进行中(in-progress)的fiber。当前节点的alternate是进行中的fiber,进行中的fiber的alternate对应的是当前的fiber。当前的fiber表示已经渲染的,进行的fiber表示还没有返回的栈中的帧。
Output
React的叶子节点。他们是渲染环境中普通的标签(例如浏览中,它们是div、span等),在jsx中,它们用小写的标签名字表示。
从概念上讲,fiber的output就是函数的返回值。每个fiber最终都有输出,但是output仅通过基础组件创建叶子节点。然后将output挂载到树上。
output的值提供给渲染器,以便可以刷新更改。例如,让我们来看一下面代码的fiber树:
const Parent1 = (props) => {
return([<Child11 />, <Child12 />])
}
const Parent2 = (props) => {
return(<Child21 />)
}
class App extends Component {
constructor(props) {
super(props)
}
render() {
<div>
<Parent1 />
<Parent2 />
</div>
}
}
ReactDOM.render(<App />, document.getElementById('root'))
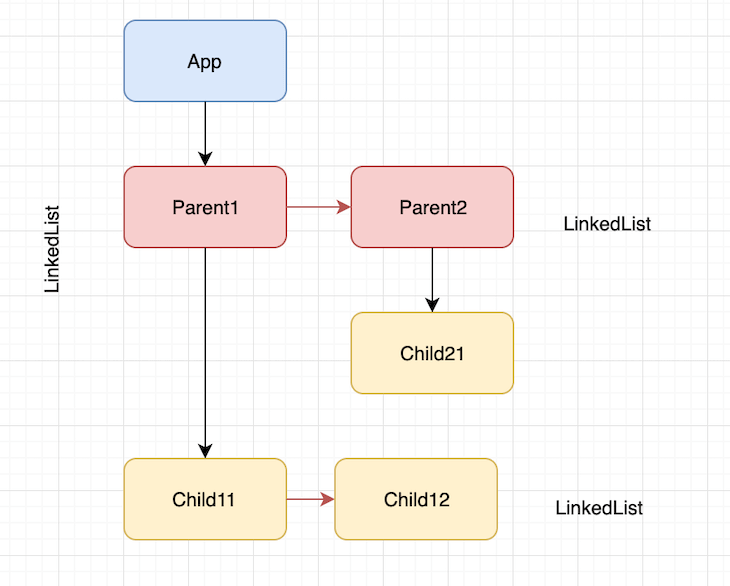
我们可以看到fiber树是由相互链接的子节点单链表和父子关系的链表组成。这种树可以使用深度优先搜索遍历。
Render phase
为了理解React是如何构建这棵树,并在其上执行reconciliation算法,我决定在React源码中写一个单元测试,来debugger这个过程。
如果你对这个过程很感兴趣,克隆React的源码,走到这个目录,增加jest测试来debbuger。我写的测试很简单,是很基本的渲染:一个带有文字的按钮。当你点击按钮的时候,app会销毁这个按钮渲染一个带有不同文字的div,此处的text是一个状态变量。
'use strict';
let React;
let ReactDOM;
describe('ReactUnderstanding', () => {
beforeEach(() => {
React = require('react');
ReactDOM = require('react-dom');
});
it('works', () => {
let instance;
class App extends React.Component {
constructor(props) {
super(props)
this.state = {
text: "hello"
}
}
handleClick = () => {
this.props.logger('before-setState', this.state.text);
this.setState({ text: "hi" })
this.props.logger('after-setState', this.state.text);
}
render() {
instance = this;
this.props.logger('render', this.state.text);
if(this.state.text === "hello") {
return (
<div>
<div>
<button onClick={this.handleClick.bind(this)}>
{this.state.text}
</button>
</div>
</div>
)} else {
return (
<div>
hello
</div>
)
}
}
}
const container = document.createElement('div');
const logger = jest.fn();
ReactDOM.render(<App logger={logger}/>, container);
console.log("clicking");
instance.handleClick();
console.log("clicked");
expect(container.innerHTML).toBe(
'<div>hello</div>'
)
expect(logger.mock.calls).toEqual(
[["render", "hello"],
["before-setState", "hello"],
["render", "hi"],
["after-setState", "hi"]]
);
})
});
在初始渲染中,React创建了一个当前树,这是最开始要渲染的树。createFiberFromTypeAndProps()是一个根据React元素的数据创建每一个React fiber的函数。当我们跑测试时,在这个函数中加一个断点,就能看到调用栈,它看起来像这样:
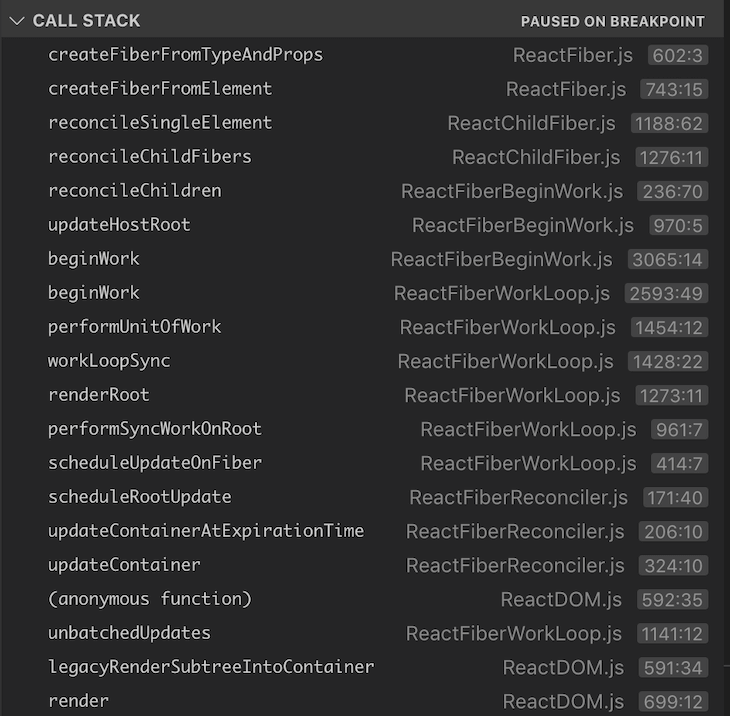
正如我们看到的,调用栈从render()开始调用,最后到createFiberFromTypeAndProps()。这里还有一些我们非常感兴趣的函数:workLoopSync(), performUnitOfWork(), beginWork()。
function workLoopSync() {
// Already timed out, so perform work without checking if we need to yield.
while (workInProgress !== null) {
workInProgress = performUnitOfWork(workInProgress);
}
}
在workLoopSync()中,React从<App>节点开始构造树,并递归的移动到子节点<div>,<div>, <button>上。workInProgress保留接下来需要更新的fiber节点引用。
performUnitOfWork()将fiber节点当作输入参数,来得到节点的alternate,并调用beginWork(),这相当于在执行栈中开始执行一个函数上下文。
当React构建树时,beginWork()只是简单的使用createFiberFromTypeAndProps()来创建fiber节点。React递归执行,最终performUnitOfWork()返回null,表示已经到了树的末尾。
但我们做instance.handleClick()(点击button触发状态的更新)会发生什么?在这种情况下,React遍历fiber树,克隆每一个节点,并检查时是否需要更新每个节点,当我们看这种场景下的调用栈,它看起来像这样:
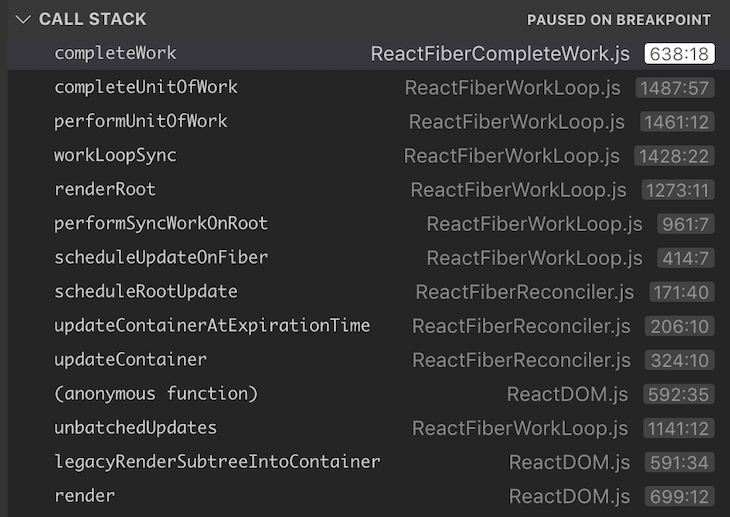
尽管我们没有在第一个调用栈中看到completeUnitOfWork() 和completeWork(),但是我们在这个图里能看到。就像performUnitOfWork()和beginWork(),这两个函数执行当前运行的完成部分,这实际上意味着已经返回到堆栈。( these two functions perform the completion part of the current execution which effectively means returning back to the stack.)
正如我们看到的这样,这四个函数配合执行,并且还控制当前正在完成的工作,这正是stack reconciler缺少的。从下图可以看出,每个fiber节点都由四个阶段组成: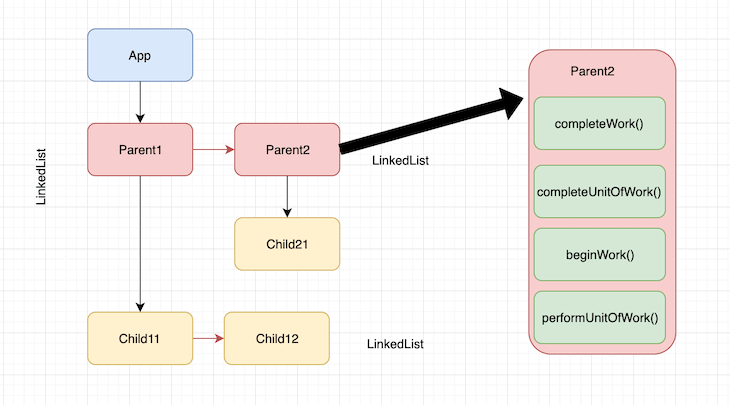
记住每个节点直到子节点和兄弟节点执行completeWork()并返回之后才会执行completeUnitOfWork()是非常重要的。例如,对于<App>,它开始执行performUnitOfWork()和beginWork(),然后继续执行Parant1的performUnitOfWork()和beginWork()等等…一旦<App/>所有的子节点执行完completeWork()后,才会回到<App/>上执行。
以上是React的渲染阶段。基于click()更新的构建的树叫做workInProgress树,它是等待渲染的草稿树。
Commit phase
一旦渲染阶段完成,React就到了提交阶段。在此阶段,它交换当前树和workInProgress树的根指针,从而完成当前树和基于click()更新的草稿树的替换。
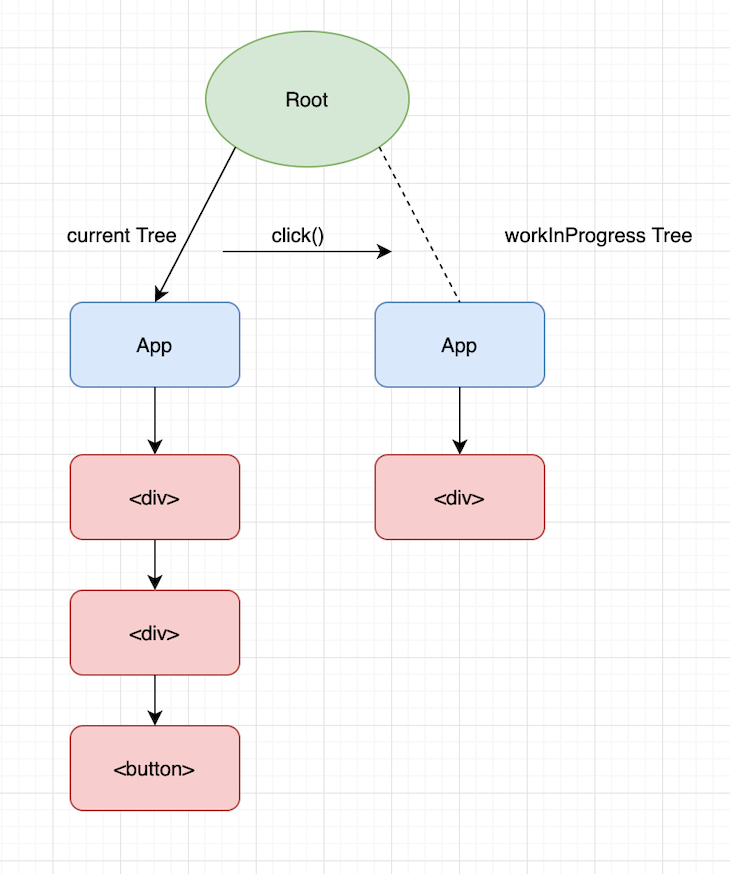
不仅如此,React还会重用之前的节点。这个优化会使从先前状态到下一个状态的的变化是一个平滑的过渡。
那16帧的时间呢?React对每个运行的工作单元有一个内部计数器,并在执行的时候不断监听时间的限制,时间一到,React就会暂停当前正在执行的工作单元,并将控制权交给主线程,让浏览器渲染。
接着,在下一帧,React回从暂停的地方继续构建树。当有足够的时间,它就会提交workInProgress树来完成渲染。
总结
为此,我强烈推荐你看 Lin Clark 的这个视频,这里她用很好的动画来解释这个算法,看起来更容易理解。(这是xx的一个视频,下面用图片代替)

希望你喜欢阅读这篇文章。
推荐: